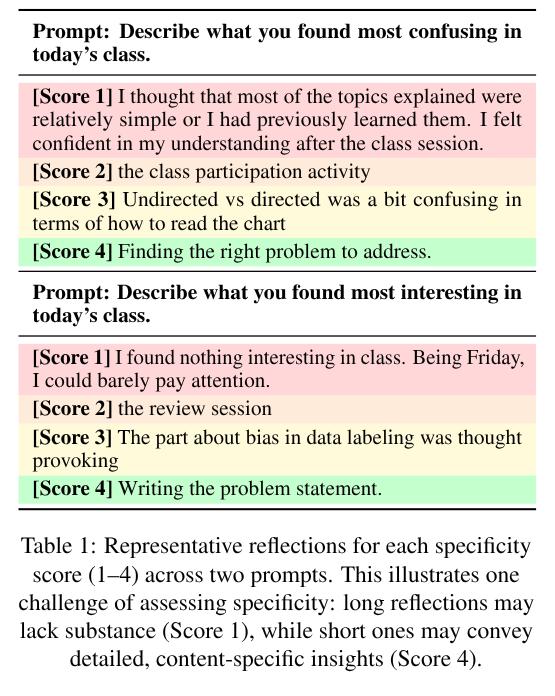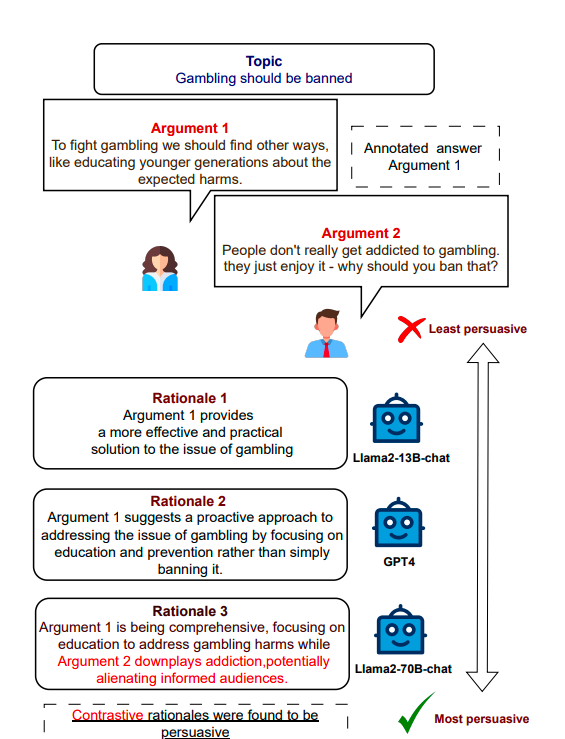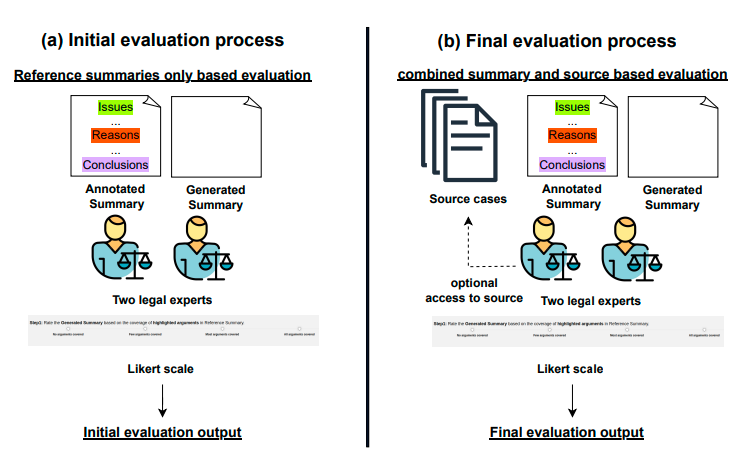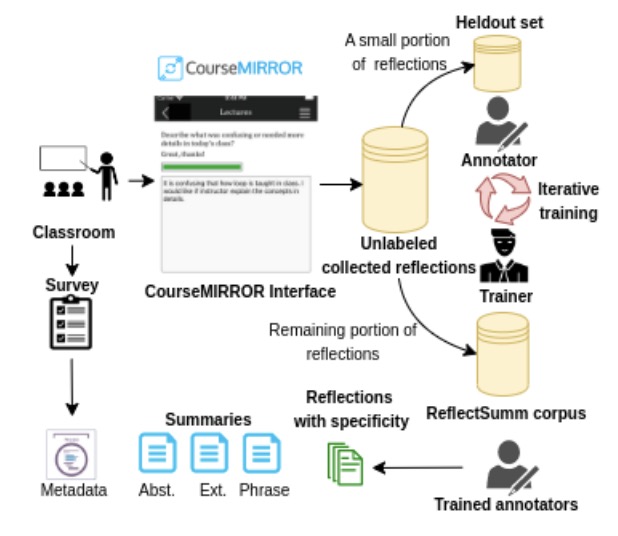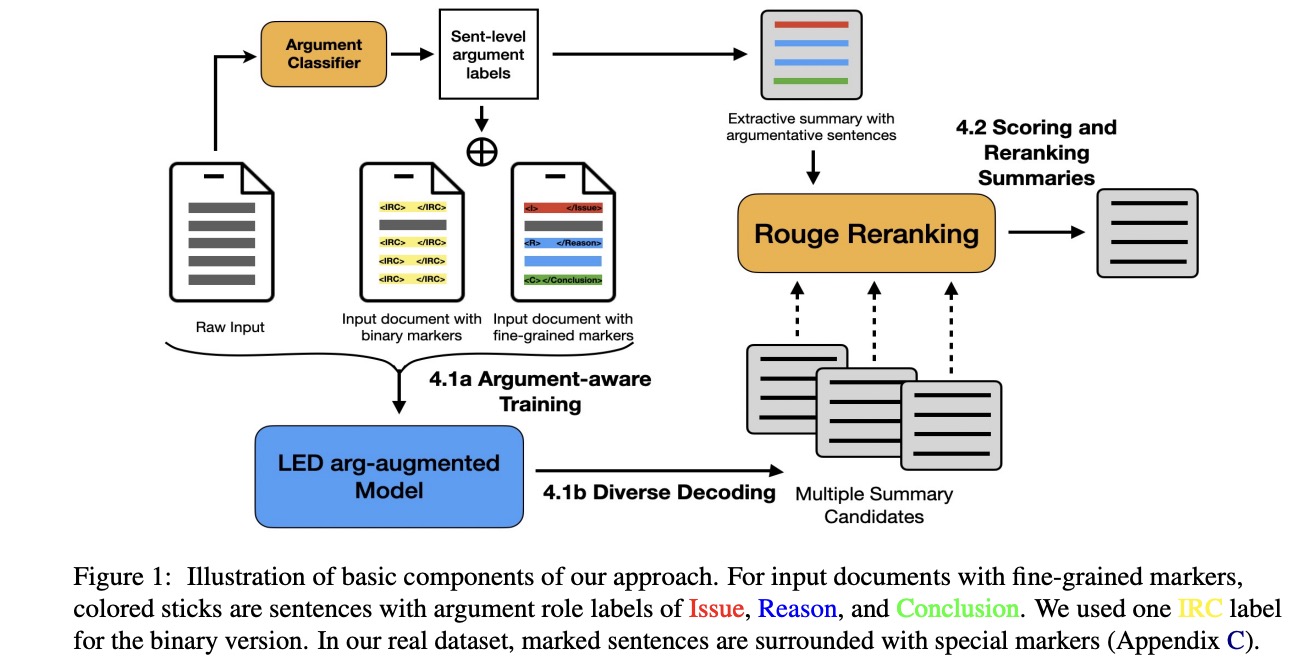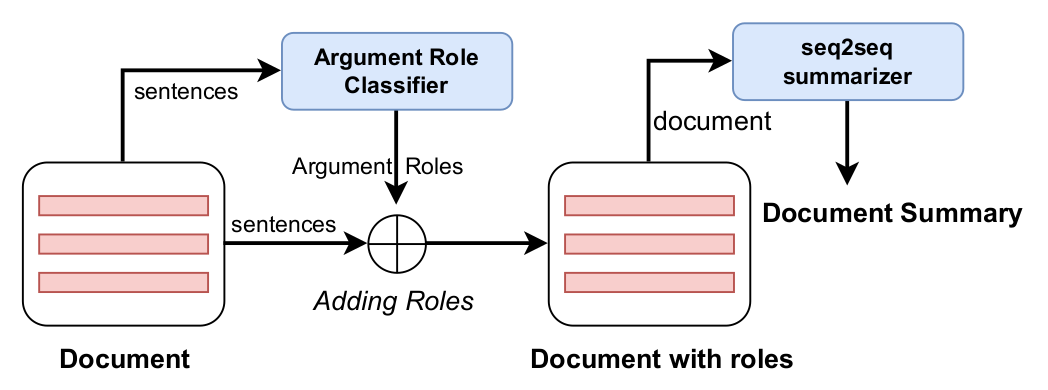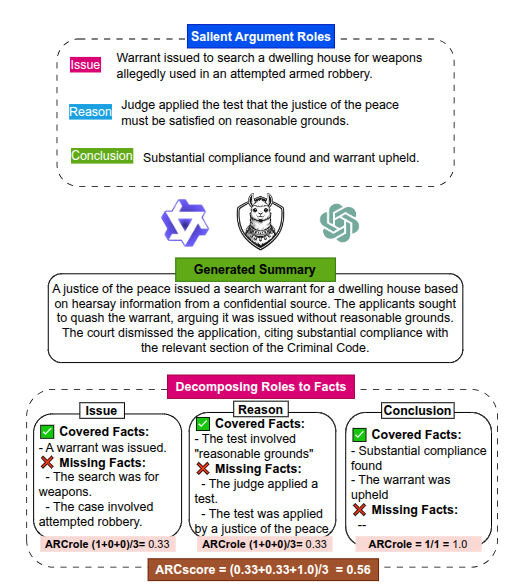
ARC: Argument Representation and Coverage Analysis for Zero-Shot Long Document Summarization with Instruction Following LLMs
Show BibTeX
@article{elaraby2025arc,
title = {ARC: Argument Representation and Coverage Analysis for Zero-Shot Long Document Summarization with Instruction Following LLMs},
author = {Elaraby, Mohamed and Litman, Diane},
journal = {arXiv preprint arXiv:2505.23654},
year = {2025},
note = {Accepted at EACL 2026 Main Conference}
}